AWS BedrockでRAG(検索拡張生成)機能を使ってみる

AWS Bedrockを使うことで、一般的な内容は簡単に問い合わせをして回答してもらえるようになりました。
ただ、このままでは自社情報など固有の情報まではAWS Bedrockの生成AIでは知りえないので回答してくれません。
そこで、ナレッジベースというRAG(検索拡張生成)機能を使ってみます。
この機能によりAWS Bedrockの生成AIに対して情報を追加で取り込ませることができます。
ただ、このままでは自社情報など固有の情報まではAWS Bedrockの生成AIでは知りえないので回答してくれません。
そこで、ナレッジベースというRAG(検索拡張生成)機能を使ってみます。
この機能によりAWS Bedrockの生成AIに対して情報を追加で取り込ませることができます。
RAG(検索拡張生成)とは?
RAG(検索拡張生成)とは、簡単に言えば、生成AIに対して追加の知識情報を与えることを意味します。
生成AIはRAGがなくとも、既に質問に対する回答機能を持ちますが、回答内容は推論に基づいて行われるため、虚偽の回答や古い情報が回答されることも多くあります。
また、一般的に知られている情報以外のことは回答できないという性質を持ちます。
そこで生成AIに対して、追加の知識ベースを追加することで、容易に情報の更新や追加、回答の正確性を高めることができるのです。
最近の生成AIのビジネス利用においても、自社に蓄積したデータを生成AIに活用させたいという目的でも
生成AIはRAGがなくとも、既に質問に対する回答機能を持ちますが、回答内容は推論に基づいて行われるため、虚偽の回答や古い情報が回答されることも多くあります。
また、一般的に知られている情報以外のことは回答できないという性質を持ちます。
そこで生成AIに対して、追加の知識ベースを追加することで、容易に情報の更新や追加、回答の正確性を高めることができるのです。
最近の生成AIのビジネス利用においても、自社に蓄積したデータを生成AIに活用させたいという目的でも
構成イメージ
AWS Bedrockでは外部データベースとして、「Amazon OpenSearch Serverless」と「Amazon Aurora PostgreSQL Serverless」が使用できます。
最近ではプレビュー状態ですが、「Amazon Neptune Analytics」も使用できる様です。
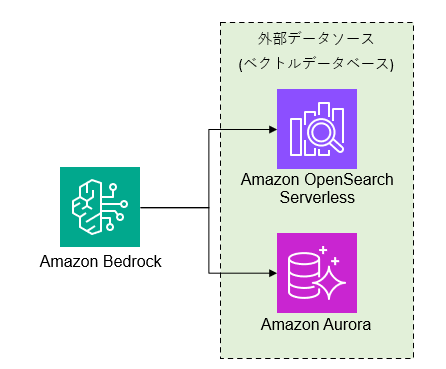
最近ではプレビュー状態ですが、「Amazon Neptune Analytics」も使用できる様です。
作成方法
作業前提
作業を行うにあたって必要な前提事項です。- データ投入用S3バケットの作成
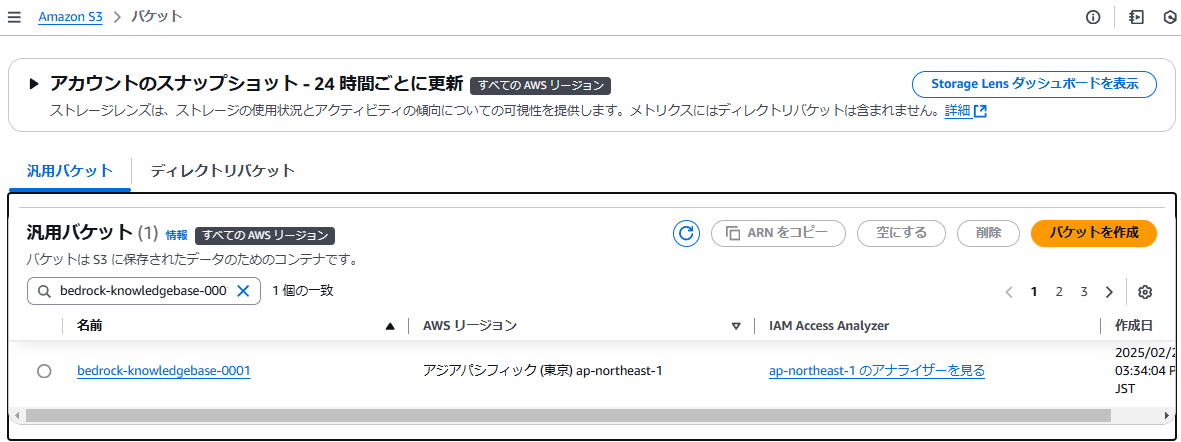
- RDSの作成(Aurora PostgreSQL Compatible)
※作成の際に「RDS Data API」を有効化して下さい。

- 作成したRDSにVector store用のDB作成
マスターユーザーを使って作成したRDSのpostgresデータベースに接続し、以下のコマンドを順に実行してください。
作成したユーザーを使ってpostgresデータベースに接続し、以下のコマンドを実行してください。CREATE EXTENSION IF NOT EXISTS vector; SELECT extversion FROM pg_extension WHERE extname='vector'; CREATE SCHEMA bedrock_integration; CREATE ROLE <ユーザー名> WITH PASSWORD '<パスワード>' LOGIN; GRANT ALL ON SCHEMA bedrock_integration to <ユーザー名>;
CREATE TABLE bedrock_integration.bedrock_kb (id uuid PRIMARY KEY, embedding vector(1536), chunks text, metadata json);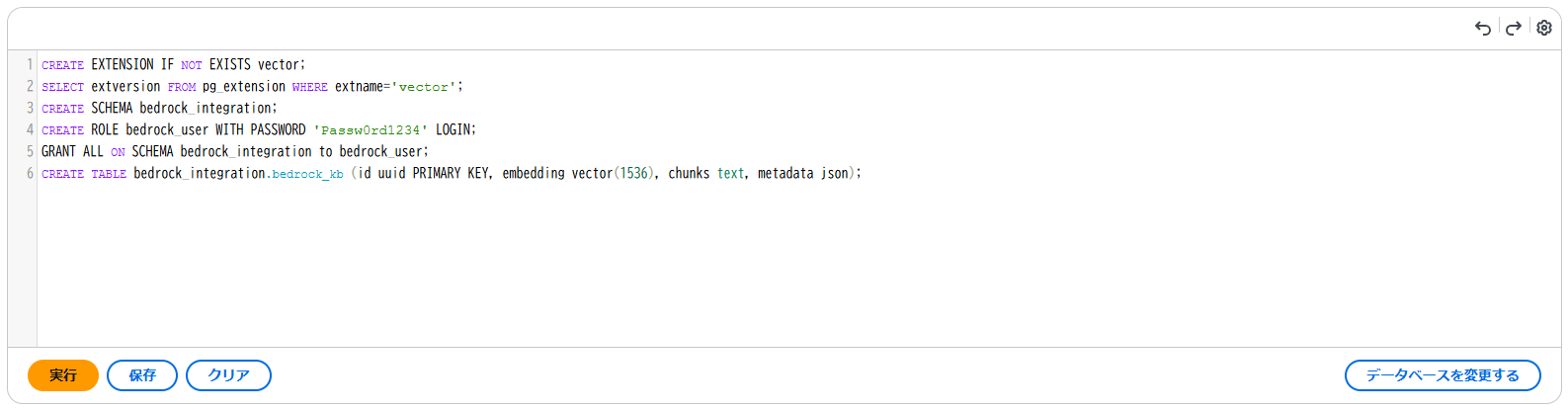
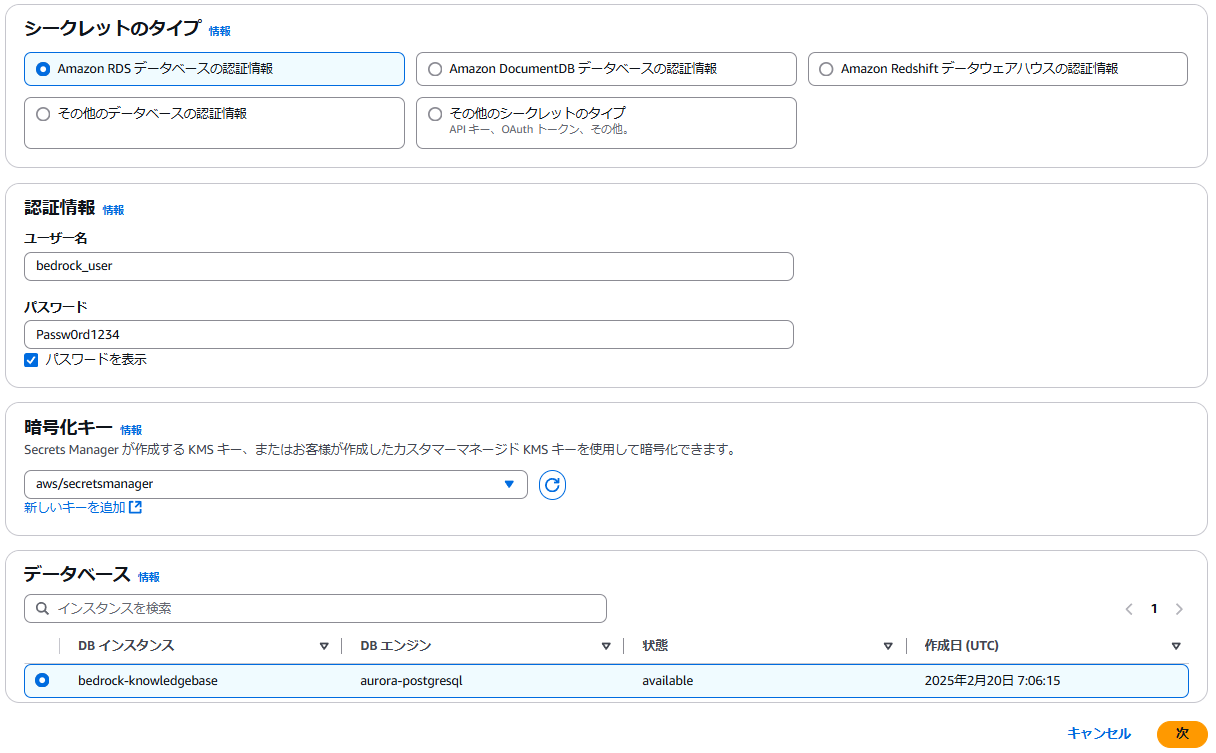
- BedrockからDBへのアクセス用にSecretManagerの作成
ナレッジベースの作成
①AWS Bedrockのナレッジベースの画面から「ナレッジベースの作成」を押下します。
②適当な名前とData source detailsで「Amazon S3」を選択し、次へ行きます。
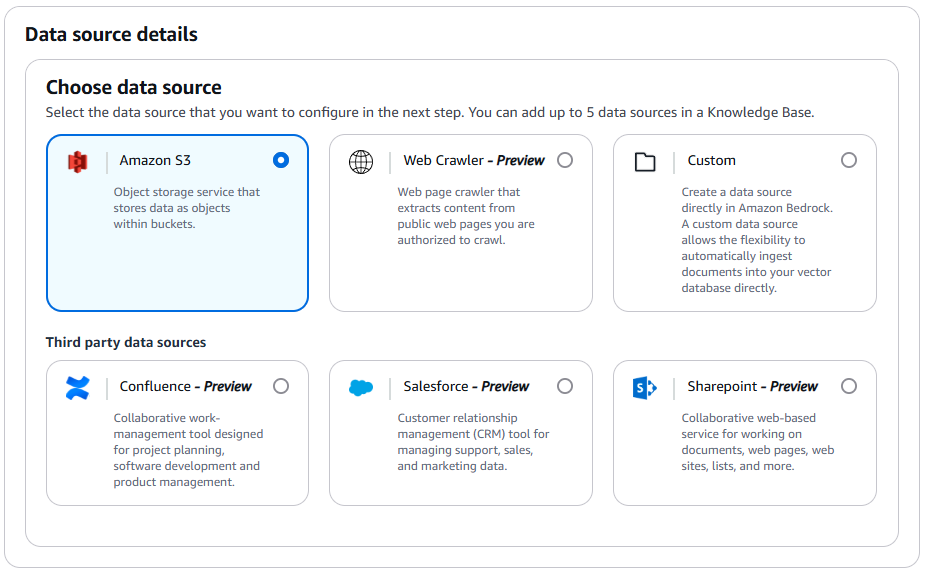
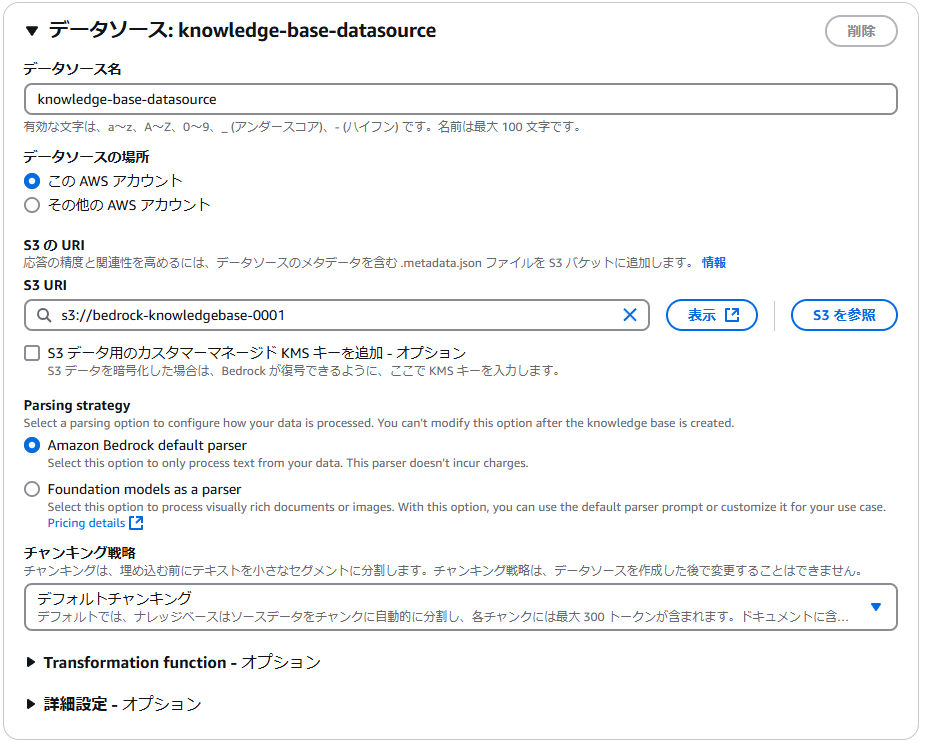
③S3 URIに作業前提で作成したS3バケットを選択し、次へ進みます。
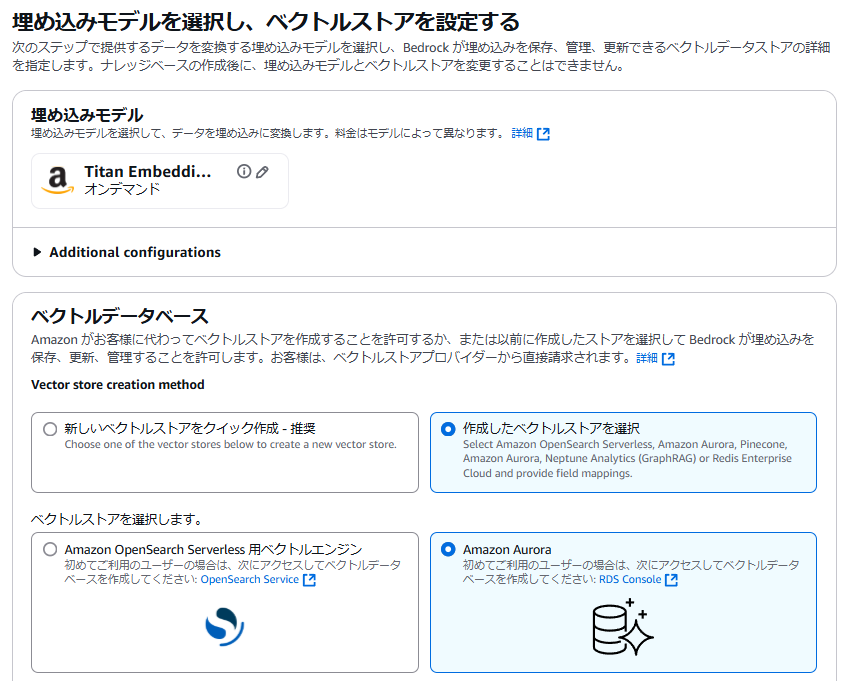
④埋め込みモデルに「Titan Embeddings G1 - Text V1.2」を選択し、ベクトルデータベースは「作成したベクトルストアを選択」にします。
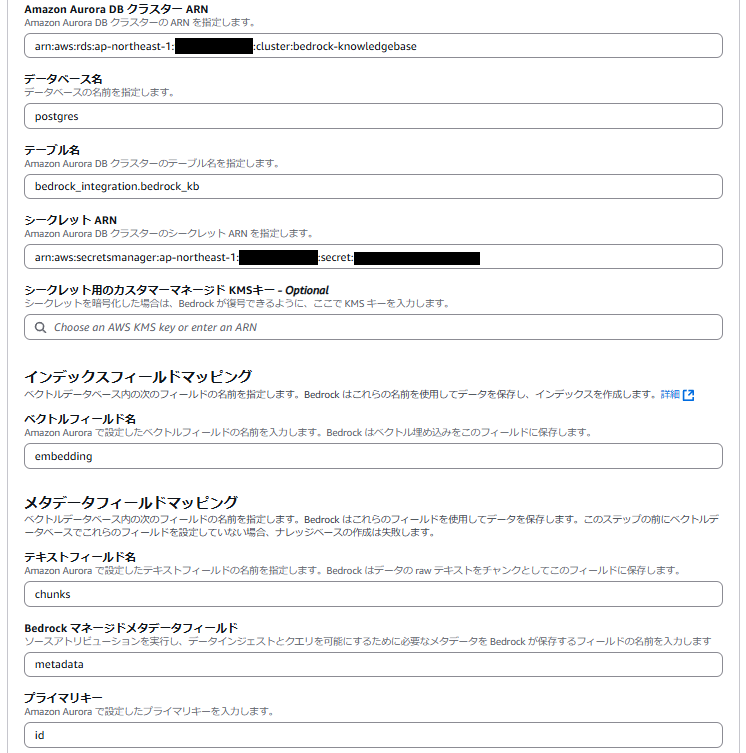
⑤作成したRDSの情報を入力していきます。
- Amazon Aurora DBクラスターARN:<作業前提で作成したRDSのARN>
- データベース名:Postgres
- テーブル名:bedrock_integration.bedrock_kb
- シークレットARN:<作業前提で作成したSevretManagerのARN>
- ベクトルフィールド名:embedding
- テキストフィールド名:chunks
- Bedrockマネージドメタデータフィールド:metadata
- プライマリキー:id
⑥確認画面で「ナレッジベースを作成」を押下すると作成が開始されます。
データ投入
①S3に投入したいデータを配置して、ナレッジベースの「同期」ボタンを押下します。
動作確認
個人情報のデータをランダムに作成してくれるサイトで、適当な情報を作ってみます。作成されたデータをcsvに変更して、S3に配置して同期しておきます。
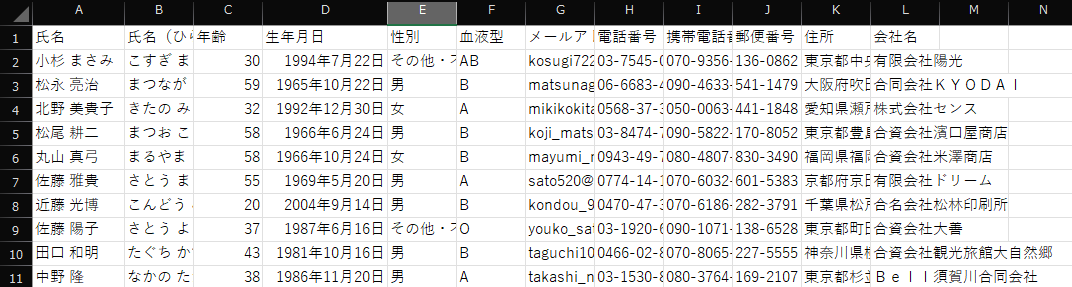
では簡単に一番上の人の年齢を尋ねてみます。
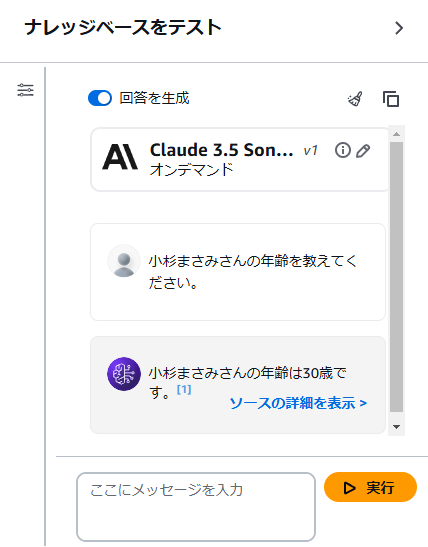
きちんと登録したデータから年齢を回答してくれました。
RDSを作成したり少し手間はありますが、S3にCSVを置くだけで簡単にBedrockが取り込んで回答してくれました。
まとめ
RDSを作成して、S3にファイルを置くだけで生成AIに読み込ませることができました。
想像以上に簡単で驚きました。
取り込むデータは「プレーンテキスト(txt)」、「マークダウン(md)」、「html」、「doc/docx」、「csv」、「xls/xlsx」、「pdf」に対応しています。
ワードやエクセルに対応しているのが素晴らしいですね。
自社内に蓄積しているデータもそのまま取り込ませて生成AIに使わせることができそうですね。
想像以上に簡単で驚きました。
取り込むデータは「プレーンテキスト(txt)」、「マークダウン(md)」、「html」、「doc/docx」、「csv」、「xls/xlsx」、「pdf」に対応しています。
ワードやエクセルに対応しているのが素晴らしいですね。
自社内に蓄積しているデータもそのまま取り込ませて生成AIに使わせることができそうですね。